
B2B 서비스의 특성 때문일까?
나는 종종 동료들과 나중에는 우리 서비스가 고객사에게 이런 것도 해주면 좋겠다~ 하는 상상을 해보기를 즐겨 했는데,
그 중 하나가
"고객사가 우리에게 물어보는 것들을 인공지능이 대신 답해줄 수 있으면 좋겠다!" 였다.
작은 규모의 스타트업이고, 인공지능을 도입할 수 있는 상황은 아니었기 때문에 그 꿈은 한 쪽으로 미뤄둔 채
서비스에 추가할 신규 기능을 쉴새없이 만들던 어느 날, 업무가 약간 여유로워지는 타이밍이 찾아왔다.
나는 이 타이밍에 AI 챗봇을 언젠가 우리가 제공할 수 있을지 가능성을 확인해보고 싶다는 의견을 말씀드렸고,
그러면 이틀 정도는 여유가 있을 듯 하니, 하고 싶다면 한 번 알아보되 부담은 갖지 말라는 답변을 주셨다.
가능성만 확인해본다고 했지만 사실 내게는 배포된 개발 버전에서 실제로 동작하는 챗봇을 보여드리겠다는 비밀스러운 목표가 있었다.
주어진 시간 : 2일
목표 비용 : 0원
1. 프론트엔드 - 백엔드 통신 구조 정하기
우선 주어진 시간이 길지 않았으므로, 나의 든든한 조력자가 알려준 랭체인 라이브러리를 사용하기로 했다.
Next.js 환경의 프론트엔드에서 question을 받으면 질문과 함께 관련 정보들을 전달받아 python 환경의 백엔드로 전달해준다.
백엔드는 python을 사용하고 있으므로 랭체인 라이브러리를 이용해 API로 통신을 하고, DB의 데이터 중 일부만 전달할 수 있다.
특히 DB에서 데이터를 가져올 때는 '누가 요청했는지(회사, 유저)'를 포함한 여러 상황에 따라 조건문을 걸어둠으로써,
권한이 있는 데이터만을 LLM에 전달하도록 만들었다.
2. LLM API 종류 정하기
Gemini 무료 티어는 OpenAI의 ChatGPT나 Claude에 비해 무료 사용량이 넉넉한 편이다.
단, 세 가지 측정 기준에 따른 제한이 존재한다.
- 분당 요청 수 (RPM)
- 분당 토큰 수 (입력) (TPM)
- 일일 요청 수 (RPD)
각 한도를 초과하면 오류가 발생한다. RPD 할당량은 태평양 표준시 자정에 재설정된다는 문구가 공식 홈페이지에 게재되어 있다.
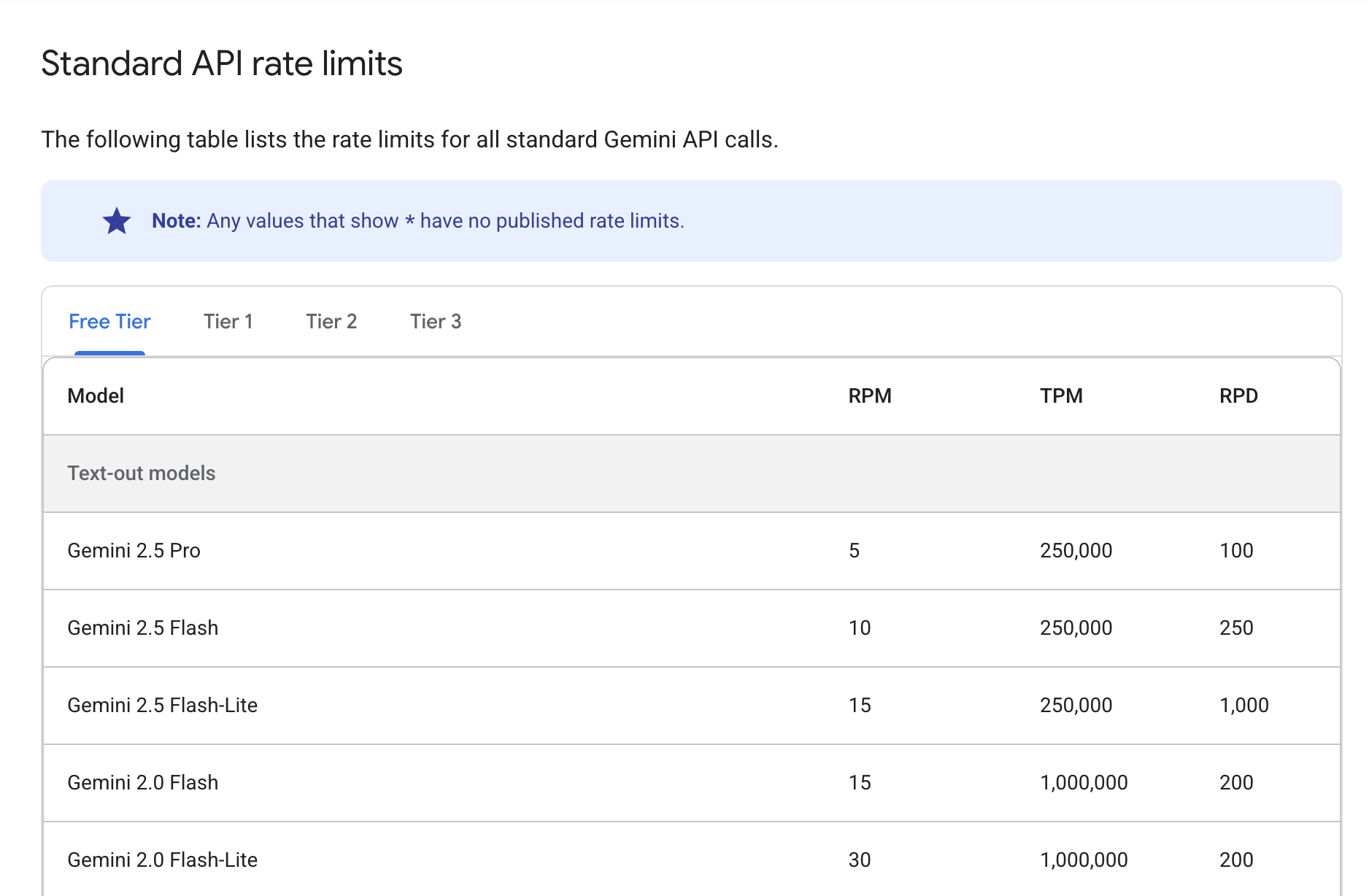
RPD는 낮더라도, RPM은 높게
실제 챗봇을 이용한다면 주로 업무 시간에 하게 될 것이므로,
일일 요청 수(RPD)가 적어도 괜찮으나
몰리는 시간대에는 최대한 많은 질문을 받을 수 있도록 분당 요청 수(RPM)은 높으면 좋겠다고 생각했다.
TPM은 높게, 모델 성능은 가볍게
DB의 데이터를 전달해서 최대한 해당 데이터를 있는 그대로 전달하는 것을 목표로 하므로,
많은 데이터를 전달하되 모델의 성능은 조금 가벼워도 괜찮다고 생각했다.
따라서 나는 Gemini 2.0 Flash-Lite가 첫 시작으로 적합하다고 판단했다.
3. Multi-Agent 구조
당시 AWS summit에서 하나투어의 생성형 AI 챗봇 도입 사례 강연을 너무나 흥미진진하게 들었다.
해당 발표 자료는 유튜브에도 공개되어 있는데, 처리 구조를 설정하는 데 많은 도움이 되었다.
하나투어 CTO님이 명확하게 잘 이해되도록 설명해주셔서 정말 좋았다.

특히 유저와 소통하는 가장 앞 단에 하나의 Supervisor AI Agent가 존재하고,
해당 Agent가 또 다른 Agent들에게 적절한 지시를 내림으로써 각 Agent는 자신이 권한을 가진 DB에 접근하는 방식이 마음에 들었다.
나는 이 방식을 응용하여 다음과 같은 흐름을 설계해보기로 했다.
1. Supervisor Agent 역할
첫째로 Supervisor Agent는 유저가 입력한 질문(Question)을 분해하여,
어떤 테이블의 어떤 권한만을 줄지 판단하여 Context_type 배열만을 반환한다.
즉 question의 context가 어떤 타입인지 파악하고 전달해주는 모델을 추가해서 토큰 사용량을 최소화하는 것이다.
이 때 프롬프트에 Context_type이 명확하게 나오도록 만드는 것이 중요했기 때문에,
사전에 Context_type 목록을 전달해준 후, 예시 질문과 결과로 Few-shot 기법을 활용해보았다.
질문: ~는?
결과: ["context_type1"]
질문: ~하고 싶어요
결과: ["context_type3", "context_type5"]
질문:{question}
결과:
2. Collaboration 방법
전달받은 결과는 내가 원하는 형태로 다시 정제한 다음, context_type 기준으로 어떤 Agent를 실행할지 결정한다.
이 때 각 Agent는 마치 회사의 인사팀, 재무팀이 가진 권한이 별개인 것처럼 DB 테이블에 대한 각각의 권한을 별개로 가지게 된다.
조회 가능한 테이블이 한정되어 있으므로, 주고받는 토큰의 양도 최소화할 수 있다!
Agent의 응답은 질문-답변 한 쌍으로, 채팅 id를 함께 기록하여 DB의 로그 테이블에 기록해두었다.
DB의 로그 테이블에 기록되는 채팅 id의 역할은
챗봇과의 대화창이 한 번 열리면 주고받는 대화 자체를 context처럼 함께 사용하여 대화가 이어진다는 느낌을 주는 것이다.
추후 채팅 목록을 관리하는 데에도 활용하면 좋겠다고 생각했다.
모든 Agent가 공통으로 사용하는 프롬프트도 넣어주었다.
예를 들어, 질문한 사람의 언어에 따라(한국어로 질문하면 한국어로, 영어로 질문하면 영어로) 맞춰 답변하는 기능 같은 것들.
프론트에서 언어를 설정하는 화면이 있기 때문에 이와 연동해주는 작업을 추가로 거쳤다.
4. 프론트엔드 챗봇 UI 구현
챗봇과 채팅할 수 있는 아이콘을 클릭하면 대화창이 모달으로 생성된다.
이 때 언어는 서비스 환경설정에서 유저가 설정한 언어를 따른다.
1. 진입 시점 : 유저는 챗봇의 환영 메세지를 전달받고, 입력창에 포커스가 되어 있다.
2. 질문 후 답변 대기 중 : 질문 후 답변을 기다리는 동안 "스피너 아이콘+답변을 작성 중입니다..."가 챗봇의 답변이 도착하기 전까지 같은 자리에서 보여진다. 이 때 입력창은 비활성화된다. (useState로 상태 관리)
3. 답변 수신 후 : 챗봇 답변이 표출되며 메세지 입력창이 활성화되며 다시 자동 포커스된다.
UX 향상을 위해 챗봇과의 대화 방법도 추가해두었다.
1. 권한에 따라 조회할 수 있는 데이터가 달라진다는 점을 알려준다. 권한이 없으면 답변이 제한될 수 있음을 암시한다.
2. 챗봇 창이 닫히면 대화가 이어지지 않는다는 점을 명확히 안내한다. 계속 대화를 원한다면 창을 열어 두어야 한다는 것을 알려준다.
3. 질문한 언어에 맞춰 답변할 수 있다는 점을 참고로 알려준다.
4. 예시 질문을 함께 제시해, 질문의 형태와 적절한 길이를 참고할 수 있도록 했다.


결론적으로 2일만에 무료로 챗봇 만들기는 잘 마무리되어 좋은 호응을 얻었다!
아직은 데모 버전에서만 아주 제한적으로 자리를 차지하고 있는 기능이지만, 회사의 데모 영상에도 향후 추가할 기능으로 소개되었다.
대표님과 룩셈부르크의 컨퍼런스에 참석했을 때도 부스에 찾아오는 사람들에게 해당 기능을 시연해볼 기회를 주셨는데,
기능을 써보면서 잘 답변하는게 신기한지 계속 cool하다고 말해주었던 어떤 라틴계 참석자가 기억에 남는다.
1명이 2일동안 0원으로 이렇게 간단하게 챗봇을 만들고, 로그까지 기록하여 관리할 수 있다는 것을 실험해볼 수 있는 좋은 기회였다.
물론 실제 회사에서는 언급된 것 이후에도 더 보강하고 추가한 작업들이 많지만, 코드를 공개하기는 어려워 전체적인 흐름만 공유해보았다.
빠르게 무료 챗봇 만들기를 기획해야 하는 분들에게 참고가 되기를 바란다 :)
'Data Science' 카테고리의 다른 글
| python pydantic이란? typing과 함께 사용법 이해하기 (0) | 2024.08.09 |
|---|---|
| 맥북 M1, M2 zsh lsd 아이콘 깨짐 문제 발생 시 해결 방법 (1) | 2024.08.08 |
| FastAPI 이해부터 router로 백엔드 API 서버 만들고 docs 문서 확인하기 (0) | 2024.08.07 |
| [오류 해결] unable to get local issuer certificate, ConnectionResetError(54, 'Connection reset by peer) + InsecureRequestWarning (0) | 2024.07.29 |
| M1 맥북 mysql 설치 및 DB 생성, workbench 설치 (0) | 2024.07.19 |




댓글