
Numerical Python을 의미하는 넘파이는 머신러닝 주요 알고리즘의 기반이 되는 선형대수 기반의 프로그램을 파이썬에서 쉽게 만들 수 있도록 지원하는 패키지다. 루프를 사용하지 않고 대량 데이터의 배열 연산이 가능해지기 때문에, 빠른 배열 연산 속도를 얻을 수 있다는 큰 장점을 가지고 있다.
넘파이 패키지의 장점이 빠른 연산이기 때문에, C/C++과 같은 저수준 언어로 프로그램을 작성하고, 넘파이에서 호출하여 빠르게 연산하는 식으로 호출이 가능하다. 효율적으로 데이터를 주고받거나 API를 호출해 통합할 수 있다는 것! 구글의 대표적인 딥러닝 프레임워크, 텐서 플로우가 이러한 방식으로 만들어져 있다.
일반적으로 데이터는 2차원 형태의 행과 열로 이뤄졌기 때문에 판다스를 주로 사용하게 되고, 넘파이는 그렇게 많이 사용하지 않는다. 하지만 많은 머신러닝 알고리즘들이 넘파이 기반으로 작성되어 있고, 입출력 데이터를 넘파이 배열 타입으로 사용하는 만큼 짚어보고 넘어갈 필요가 있겠다는 점에서 나 또한 전체적으로 정리해둔다.
넘파이 설치
넘파이 설치는 아래와 같이 간단하게 할 수 있다.
import numpy as np넘파이의 기반 데이터 타입은 ndarray(다차원 행렬 자료구조)이다.
array() 함수를 통해 다양한 인자(파이썬 리스트 등)를 입력해 ndarray로 변환할 수 있다.
넘파이 차원 확인
ndarray 배열의 shape 변수는 행과 열의 수를 나타내는데, 배열의 차원이 1차원인지 2차원인지 잘 구분할 수 있어야 한다.
먼저 파이썬의 리스트 객체를 이용해 아래와 같이 행렬을 생성할 수 있다.
(행렬 [1,2,3]은 1차원이고 [[1,2,3]]은 2차원이라 생각하면 편하다.)
리스트[]는 1차원, 리스트의 리스트[[ ]]는 2차원 형태로 배열의 차원(크기)을 쉽게 표현할 수 있어서 array() 함수의 인자로 많이 사용된다.
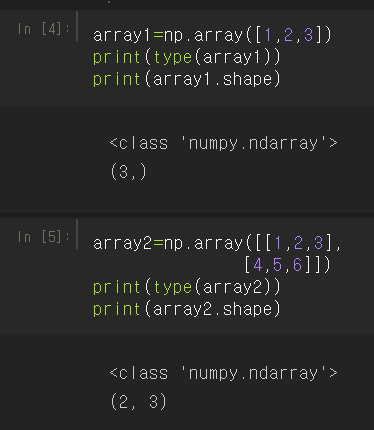

array1의 shape 변수는(3,) = 1차원 array이며, 3개의 데이터를 가지고 있다.
array2의 shape 변수는(2,3) = 2차원 array이며, 2개의 row와 3개의 column 즉 6개의 데이터를 가지고 있다.
array3의 shape 변수는 (1,3) = 2차원 array이며, 1개의 row와 3개의 column 즉 3개의 데이터를 가지고 있다.
3차원 데이터는 어떨까?
array4의 shape 변수는 (1,1,3) = 3차원 array이며 1*1*3= 3개의 데이터를 가지고 있다.
array1과 array3, array4의 데이터 건수는 동일하지만 차원은 다르다. 이렇게 차원이 달라서 오류가 발생하는 경우가 많다.
명확히 1차원 데이터 혹은 n차원 데이터를 요구받는 경우, 차원의 차수를 reshape()로 변경할 수 있는데 이 부분은 다음 포스팅에서 자세히 알아보자.
현재 차원이 몇차원인지 바로 뽑아내는 함수는 ndim이다. 아래와 같이 차원을 확인할 수 있다.

넘파이 데이터 타입 확인
✔ ndarray에는 숫자/문자열/bool 모두 가능하지만, 한 개의 ndarray에는 같은 데이터 타입만 가능하다.
리스트는 서로 다른 데이터 타입을 가질 수 있기 때문에, 리스트에서 ndarray로 변경할 때 데이터 타입이 다르다면 크기가 더 큰 데이터 타입으로 일괄 변경된다.
아래와 같이 dtype 속성으로 확인할 수 있다.

넘파이 데이터 타입 변경
데이터 타입은 astype으로 변경해줄 수 있다.
만약 실수인 float 데이터 타입을 정수인 int로 변환하게 되면 소수점이 잘리게 되므로,
메모리를 절약하는 것도 좋지만 데이터 손실이 없도록 유의하자.

'Data Science' 카테고리의 다른 글
| [Numpy] 넘파이 reshape 차원 추가 축소 변경하기 (0) | 2022.08.03 |
|---|---|
| [Numpy] 넘파이 배열 생성 arange range 차이+파이썬 빈 배열 만들기 (0) | 2022.08.02 |
| Visual Studio Build Tools 설치 (0) | 2022.08.01 |
| R을 사용하던 데이터 분석가는 왜 파이썬 머신러닝 공부를 시작했을까 (0) | 2022.08.01 |
| 파이썬 머신러닝 완벽 가이드 일명 공룡책 (0) | 2022.07.31 |




댓글