
이번 포스팅은 경사하강법과 함께 지난 포스팅에서 다뤘던 신경망에 대해서 좀 더 자세히 분석해 보는 것으로, 지난 포스팅과 내용이 이어집니다.
목표 : 손글씨로 적은 숫자 인식
입력층
28x28픽셀로 이루어진 숫자 이미지의 각 픽셀은 0~1 사이의 밝기를 의미하며, 이들이 입력층의 784개 뉴런을 형성하고 뉴런의 활성치를 결정한다.
은닉층
다음 층의 각 뉴런의 활성치는 sum(가중치x이전 층의 활성치)과 bias에 의해서 결정된다.
이 합계에 ReLU 함수를 취한다.
결론적으로 임의로 설정한 두 개의 은닉층은 13,000여개의 가중치와 bias를 가지고 있으며, 이 값들이 신경망이 실제로 어떻게 작동하는지를 결정한다.
출력층
신경망이 주어진 숫자를 분류할 때, 마지막 층에서 가장 밝은 열 개의 뉴런 중 하나를 대응시킨다.
지난 예시에서, 두 번째 층은 작은 조각들로 이루어진 숫자의 테두리를 찾고, 세 번째 층은 o와 | 등의 패턴을 찾고, 마지막에 저 패턴을 조합해 숫자를 인식했다.
테스트 방식은 신경망을 훈련시킨 후, 이전에 보여주지 않았던 데이터를 더 많이 보여준다. 그러면 신경망이 새로운 이미지를 얼마나 잘 분류하는지 알 수 있다. MNIST 소속 사람들이 제공한 숫자 손글씨 데이터를 계속해서 예시로 들어보자.
기계학습은 사실 sf소설 속의 이미지보다 미적분 예제에 더 가깝다. 근본적으로는 특정 함수의 최솟값을 찾는 일로 요약될 수 있다.
각 뉴런이 이전 층의 모든 뉴런과 결정되어 있고, 각각의 활성화를 결정하는 가중치는 일종의 연결의 세기이고, bias는 뉴런의 활성화 여부를 만든다고 하자.
만일 무작위로 가중치와 bias를 주면, 끔찍한 결과가 나올 것이다.
잘 훈련된 모델이라면 정답의 가중치만 1에 가깝고, 나머지는 0에 가까워야 할 것이므로 이때 'Cost'를 사용하게 된다.
Cost는 잘못된 출력과 원하는 출력의 차의 제곱을 모두 더한 결과로, 위에서부터 0,1,2,3,4..이고 3의 cost를 구하고자 할 때는 이런 식으로 표현될 수 있다.
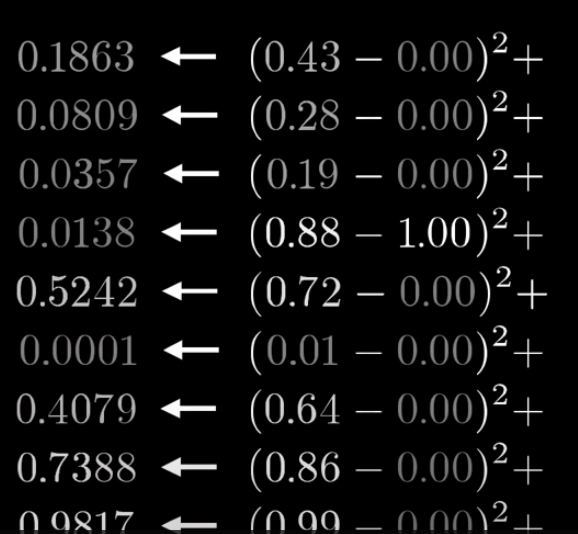
신경망이 이미지를 올바르게 분류한다면 이 합계는 작아지지만, 그렇지 않다면 커진다.
즉, Cost는 '신경망이 얼마나 엉망인지'를 나타내는 값이다.
그렇다면 우리는 수만 가지 학습 전체에 대한 평균 cost를 검토해서 최대한 작게 만들면 된다.
신경망 자체는 기본적으로 함수이다. 784개의 픽셀을 input으로 받아서, 10개의 숫자를 output으로 내며, parameters는 13,000개 weight와 biases에 의해 매개변수화되어 있다.
이렇게 함수 측면에서 cost함수를 다시 보면,
input으로 13,000개 weight, biases를 받고,
Output으로 이 weight/bias가 적절한지 아닌지를 나타내는 숫자 하나를 출력하는데,
parameter로는 아주 많은 훈련 데이터, 이 훈련 데이터들에 대한 신경망의 행동에 따라 이 숫자인 output이 결정된다.
가중치와 bias를 어떻게 바꿔야 더 나아질지 알려주는 것이 중요하다.
단순히 입력값 하나에 출력값 하나인 함수에서 출력값을 최소화하는 방법에 대해 생각해보자.
한 입력값이 주어졌을 때, 어떤 방향으로 이동해야 최소값을 찾을 수 있는가? 에 대한 문제에 답하려면,
기울기를 알고 있을 때, 음수면 오른쪽, 양수면 왼쪽으로 이동하면 최소값을 찾을 수 있다.
계속 기울기를 확인하면서, 함수의 local minimum에 도착할 수 있다. (출발지점을 어디로 했느냐에 따라 각자 다른 local minimum에 도착할 것이므로, 지금 내가 찾은 값이 최적의 cost라는 보장은 없을 것이다.)
*만약 한 번에 이동시킬 거리를 기울기에 비례해서 결정한다면, 오버슈팅을 방지하는 데 도움이 될 것이다.
두 개의 입력, 하나의 출력을 가진다고 해보자. 그러면 함수의 기울기 대신 공간에서 어디로 이동해야 할지를 생각해야 한다.
함수의 기울기(gradient)는 가장 가파른 상승 방향을 알려준다. 즉, 함숫값을 가장 빠르게 높일 수 있는 방향이다.
그러면 반대로 gradient의 음의 방향은 가장 빠르게 함숫값을 낮추는 방향이 된다.
gradient vector의 길이는 가장 가파른 경사가 얼마나 가파른지에 대한 지표이기도 하다.
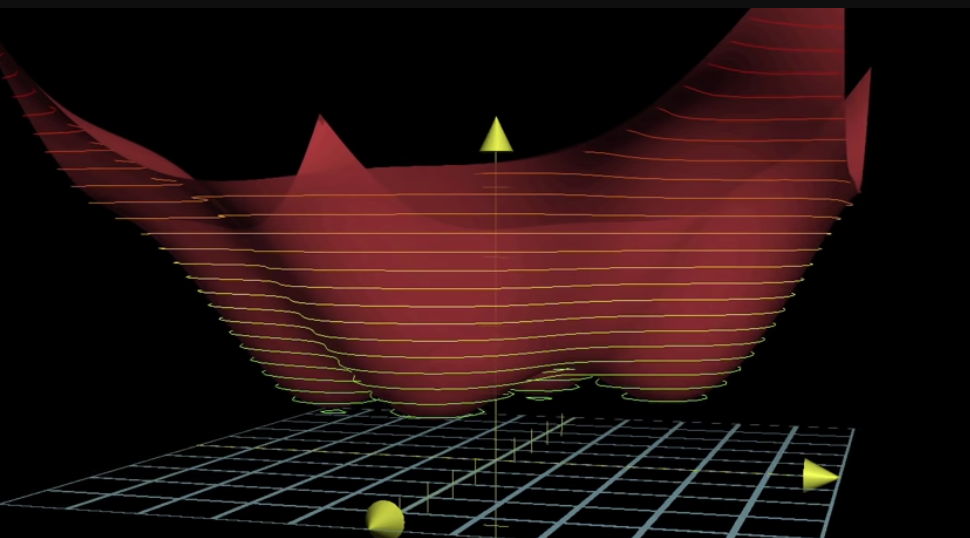
다시 우리 신경망으로 돌아와서, 13,000개의 weight, bias를 거대한 열 벡터로 조직했다면, cost함수의 gradient의 음의 방향은 그냥 벡터이다. 이 벡터는 어떤 방향이 cost함수를 가장 빠르게 감소시키는지를 알려준다.
cost함수는 모든 훈련 데이터의 평균 cost를 가져오므로, 이 결괏값을 낮춘다는 건 전체적으로 더 나은 성능을 만든다는 것이다.
이 gradient 계산을 효과적으로 만드는 알고리즘이 신경망이 얼마나 효과적으로 배울지를 결정하는 핵심 요소고, 그게 바로 오차역전파(back propagation)이다.
구현 세부사항의 독립성(independent of implementation details)
신경망 학습은 그저 cost함수를 최소화하는 것 뿐, cost함수가 매끄러운 출력을 갖게 하는 게 중요하다. 그래야 내리막을 매끄럽게 내려가면서 local minimum을 찾을 수 있을 것이다. 그래서 인공 뉴런들은 단순히 활성화/비활성화가 아니라 연속적인 활성화 값을 갖는다.
경사하강법(Gradient descent)
그래프의 골짜기, 즉 cost 함수의 local minimum으로 가는 방법.
음의 gradient의 각 요소들을 통해서 우리는 두 가지를 알 수 있다.
gradient의 부호 = 입력 벡터의 요소가 커질지 작아질지
상대적인 크기 = 어떤 요소를 조정해야 더 큰 영향을 미칠지

이건 출발점에 불과하다. 이 신경망은 아주 오래된 것이므로 이후로 많은 NN 네트워크나, LSTM에 대해서 배워야 한다.
*가중치들을 시각화해보면, 독립된 테두리보다는 희미한 패턴들로 되어있다.
우리가 원했던 방식(2단계에서 조각, 3단계에서 패턴)은 아니지만 cost는 자신만의 happy little local minimum값을 찾은 것!
*cost함수를 최소화한다는 건 이미지에 나타나는 구조를 분류하는 걸까? 그냥 기억하는 걸까?
올바른 분류가 무엇인지에 대한 데이터셋을 기억하는 것이다.
randomly-labeled data는 cost함수가 거의 직선에 가깝게 천천히 하강하는데,
제대로 된 labeled-data는 올바른 가중치를 찾아 높은 정확도를 얻기 위해 가능한 local minimum 값을 찾는다면 어느 순간 좋은 정확도 수준으로 갑자기 뚝 떨어지므로 local min값을 찾기가 더 쉽다.
재밌는 점은, "The loss surfaces of Multilayer networks" (클릭 시 다운로드 가능) 논문을 보면,
결과적으로 최적화된 환경을 보면 신경망이 배우려고 하는 local minimum들은 거의 동등한 가치를 갖는다. 즉 데이터셋이 구조화돼 있다면 local minimum 값들은 더 쉽게 찾을 수 있다.
*3Blue1Brown의 유튜브 영상을 바탕으로 작성된 자료로, 저작권은 원작자에게 있습니다.
'Data Science' 카테고리의 다른 글
| ANN RNN LSTM 딥러닝 알고리즘 모델 구조 설명 (0) | 2023.04.09 |
|---|---|
| 역전파(back propagation) 알고리즘이란? +미분 수식까지 (0) | 2023.04.05 |
| 딥러닝 인공 신경망과 뉴런의 구조 원리 개념 짚기 (0) | 2023.04.04 |
| 인공지능 머신러닝 딥러닝 개념 차이 관계 간단정리! (0) | 2023.04.04 |
| 실리콘 M2 맥북에 tensorflow, pytorch 설치 및 GPU 가속 사용 설정 방법 (0) | 2023.04.01 |




댓글