
Vision Transformer(ViT)
Vision transformer는 2021년에 "AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE"이라는 논문에서 제안된 것으로, image classification에 그 목적이 있다.
NLP 분야에서 SOTA 성능을 달성한 transformer를 이미지에도 적용하는 방법을 소개하고 있다.
transformer의 주요 개념 중 하나인 self-attention이 vision task에서는 어떻게 적용될까?
바로 각 픽셀이 다른 픽셀에 어떻게 영향을 주는가?에 대한 self-attention을 구한다.

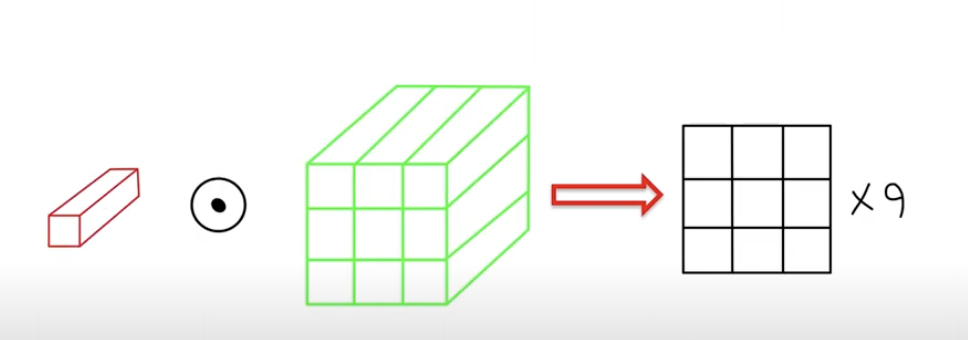
왼쪽 아래가 원래의 이미지를 9개의 patch로 잘라둔 것이다.
이미지 patch들도 결국 픽셀과 차원으로 이루어져 있으므로, 이미지 patch들을 1차원으로 flatten시켜준 후, classification에 사용한다.
transformer는 한 번에 계산하므로 위치에 대한 정보를 제공해줘야 하고 positional embedding이 그 역할을 한다.
positional embedding을 그림으로 그려보면 아래와 같이 픽셀 위치에 따라 왼쪽 위의 이미지는 왼쪽 위의 코사인 유사도가 높고, 중앙의 이미지는 중앙의 코사인 유사도가 높게 된다.

비전 태스크에서는 pos embedding이 필요없다는 이야기도 나오고 있다고도 하니 해당 부분에 대해서는 좀 더 생각해볼 거리가 있을 듯 하다.
---
다시 전체 구조 그림을 보면서 생각해보자.
각각 임베딩된 9개의 패치가 Input으로 들어가면, 각각을 모두 Norm시켜준 후 concat으로 합쳐준다.
이제 self attention 구조에 들어가기 위해 벡터에 weight를 곱해서 q,k,v로 나눠준다.
multi-head-attention 구조를 반복하면서 self attention을 반복 수행한다.
그 다음, skip connection 기법을 통해서
multihead attention을 통과한 output과, 통과하지 않은 원래의 값을 더해서 기존 값을 보존해준다.
다시 Norm 취해주고, MLP 통과한 값과 기존의 값을 한번 더 더해준다.
Transformer Encoder의 아웃풋은, MLP를 통해서 최종적으로 어떤 이미지인지 Classification 해주게 된다.
ViT에서 Q,K,V의 의미
Q,K,V는 이미지에서 어떤 의미를 가지는지 궁금해서 ChatGPT에게 물어보았다.
5x5 픽셀의 이미지가 있다고 하자. 이미지의 경우, 각 픽셀은 입력 데이터의 위치를 나타낸다.
Q(Query) : Q는 질문을 하는 벡터이다. 각 위치에 대해서, 해당 위치와 다른 위치 간의 관계를 모델링하기 위해 사용된다.
예를 들어, 5번째 픽셀의 Q벡터는 그 픽셀과 다른 위치들의 유사도를 측정해서 관계를 파악하는 데 사용될 것이다.
K(Key) : Key벡터는 유사도를 측정하기 위한 기준이 된다. 각 위치의 K벡터는 입력 데이터의 표현을 나타내며, 다른 위치와의 유사도를 측정하는 데 사용된다.
V(Value) : 입력 데이터의 실제 정보를 담은 벡터로, 유사도에 따라 가중 평균을 계산할 때 사용한다.
각 픽셀의 V벡터는 해당 픽셀에 있는 이미지의 특징이나 정보를 포함하고 있다.
---
이미지를 9개의 패치로 나눴을 때를 예시로 들어보자.

1. 9개로 나눈 각 패치를 1차원으로 만들어준다.
2. Linear Projection을 통해서 하나의 벡터로 만들어준다. 이 벡터의 사이즈는 각 vector demention x 9.
3. 3배의 dim으로 늘린 다음 이걸 3등분해서 각각을 Q,K,V로 할당해준다.
4. Multihead Attention이므로, 각 쿼리 안에 헤드 개수만큼 만들어서 연산을 해줄 것이다.
각 쿼리는 전체 키 벡터에 dot product 연산을 수행한다.
5. patch가 9개이므로 총 9개의 결과가 나오게 된다.

6. 이 결과에 softmax를 취해주면 attention score가 된다.
7. 이 값을 다시 한 번 전체 value와 dot product 연산을 취해준다.
8. 최종적으로 attention modul의 output vector를 출력한다.
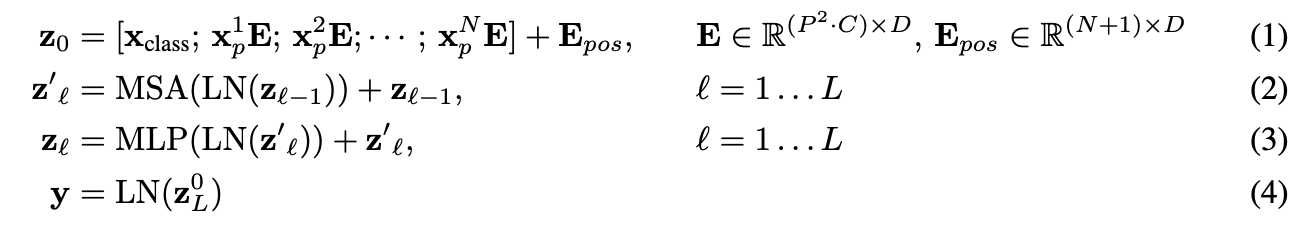
수식을 정리해보자.
z0 = transformer에 처음으로 입력되는 값. xp1 :패치 1번에 대한 변환, E : D차원으로 투영. 이게 벡터로 묶여 있다.
이렇게 각각의 linear projection된 patch들에 positional embedding을 더해준다.
z't = 해당 값을 Normalization(LN) 후, MSA(multihead self attention)에 input으로 넣어주고, 기존 값을 residual connection 기법으로 그대로 더해줘서 값을 보존해준다.
zl = 이렇게 transformer 모듈을 통과한 output 값을 한 번 더 LN 후, MLP(multi layer perceptron)를 통과하고 residual connection 기법으로 한 번 더 기존의 값을 더해준다.
y = 최종적으로 LN을 통해서 output인 y벡터가 나오게 된다.
출력된 y vector를 이용해서 이미지 classification을 수행하게 된다.
vision transformer의 특징
1차원 인풋을 받으므로, 2D 패치(N)을 1차원으로 flatten시킨다.
이렇게 flatten시킨 patch들은 학습이 가능한 벡터로 바꿔준다.
hybrid architecture : 여기서는 원본 이미지를 패치로 잘라서 linear projection을 통해 벡터로 만들었지만, CNN에 의한 피처맵을 transformer의 input으로 넣는 것도 가능하다.
유의점
트랜스포머는 많은 양의 데이터를 필요로 하기 때문에, 데이터 양이 적다면 SOTA 성능을 달성하기는 힘들 수 있다.
충분히 많은 데이터에서 사전학습된 모델이 아니면 크게 성능 향상이 힘들다.
그래서 이미지넷으로도 모자라고, 거대한 양의 학습이 된 걸 파인튜닝해야만 하므로 6억 장 정도의 이미지를 학습시켰다. 그래서 이 모델을 가져다 쓰는 게 현실적인 방안이다.
참고자료 출처
https://www.youtube.com/watch?v=QkwNdgXcfkg&ab_channel=%ED%85%90%EC%B4%88 https://www.youtube.com/watch?v=91Qipj5NMnk&ab_channel=%EC%97%94%EC%9E%90%EC%9D%B4%EB%84%88TV
*추가로 공부할 자료 : seq2seq부터 ViT까지 잘 정리해주신 영상
https://www.youtube.com/watch?v=bgsYOGhpxDc&ab_channel=%E2%80%8D%EA%B9%80%EC%84%B1%EB%B2%94%5B%EC%86%8C%EC%9E%A5%2F%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5%EA%B3%B5%ED%95%99%EC%97%B0%EA%B5%AC%EC%86%8C%5D
'Data Science' 카테고리의 다른 글
| google analytics란? GA4 자격증 시험 (0) | 2023.05.23 |
|---|---|
| 티스토리 블로그 google analytics GA4 시작하기 (0) | 2023.05.23 |
| 가상환경 Kaggle API 사용법 캐글 데이터 다운받기 (0) | 2023.05.14 |
| M2 맥북 아나콘다 가상환경 Okt 사용자 사전 편집 방법 (0) | 2023.05.11 |
| Attention is all you need 논문 리뷰+코드 실습 (0) | 2023.04.26 |




댓글