
판다스에서 원하는 행만 혹은 열만 선택하기, 즉 특정 데이터 선택을 위한 데이터 셀렉션과 필터링은 넘파이와 비슷하기도 하고 다르기도 하다. 넘파이에서 []를 이용해서 단일 값 추출, 슬라이싱 등을 통해 데이터를 추출했는데, 판다스에서는 iloc[]와 loc[]를 이용한다. 먼저 판다스 데이터프레임의 [] 연산자에 대해서도 이해해보자.
Pandas Dataframe []
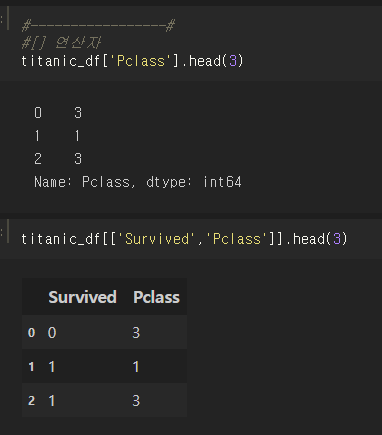
데이터 프레임 바로 뒤, [] 안에 들어갈 수 있는 건 칼럼 명 문자, 칼럼 명의 리스트 객체, 인덱스로 변환 가능한 표현식이다.
한 마디로 칼럼을 지정할 수 있는 연산자이다.
데이터프레임명['칼럼명']으로 특정 칼럼을 선택할 수 있고,
데이터프레임명[['칼럼명1', '칼럼명2']] 와 같이 여러 칼럼 선택도 가능하다.
titanic_df[0]처럼 숫자 값을 입력하면 오류가 발생한다.
하지만 위에서 언급한 것처럼, titanic_df [0:2]와 같이 인덱스 형태로 변환 가능한 표현식은 입력 가능하다.
(이 방법은 혼동을 줄 수 있으므로, 최대한 사용하지 않는 것이 좋다)
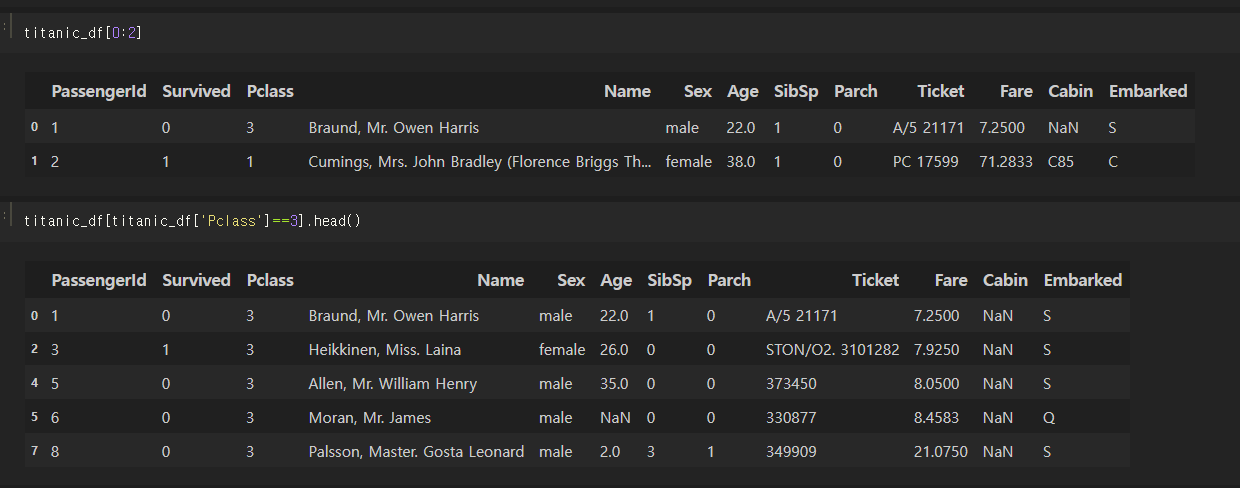
titanic_df[titanic_df['Pclass']==3].head() 와 같이 원하는 조건을 설정하여 데이터를 조회할 수 있는 불린 인덱싱도 가능하다. [] 연산자 안에는 다양한 인자를 사용할 수 있는데, 그렇기 때문에 오히려 혼란을 초래할 수 있다. 실제로는 이렇게 특정 칼럼명이나 칼럼 리스트를 지정해서 명확하게 이름을 파악할 수 있도록 사용하는 것이 혼동을 줄일 수 있다.
판다스 ix[] 연산자
초기에 ix[0,'Pclass']와 같이 행과 열을 지정해주어서 인덱스 값이 0이고 칼럼 명이 Pclass인 데이터를 추출할 수 있는 기능을 제공했다. ix[0,2]와 같이 인덱스 0인 행의 세 번째 칼럼의 값을 뽑아내는 등 다양하게 활용이 가능한 기능이었으나, 시간이 지나면서 이러한 방식의 문제점이 발생되었다.
전자와 같은 칼럼 명칭(label) 기반 인덱싱과 칼럼 위치(position) 기반 인덱싱을 둘 다 제공하게 되면서 혼돈을 주었기 때문이다. 예를 들어, index가 0부터 시작하는 게 마음에 들지 않아서 1부터 다시 매겨둔 사람이 있다고 하자. 그러면 ix[0,1]을 입력하면 index값이 0인 Key를 찾을 수 없으니까 ix[1,1]을 입력해야 첫 번째 행의 두 번째 열 위치에 있는 데이터 값을 얻을 수 있다.
결과적으로 데이터프레임의 index는 명칭 기반 인덱싱이기는 하지만, 코드에 혼란을 초래할 가능성이 있다.
그래서 ix 대신 아래와 같은 두 가지로 분리를 해 두었다. (ix 연산자는 곧 지원이 되지 않을 예정이니 사용하지 않도록 하자.)
명칭(label) 기반 인덱싱은 loc[] 연산자,
위치(position) 기반 인덱싱은 iloc[] 연산자.
DataFrame iloc[]
iloc[]는 위치 기반 인덱싱만 허용하므로 df.iloc[0,0]과 같이 행과 열 위치에 입력하면 된다.
행과 열 값으로 integer나 integer형의 슬라이싱, 팬시 리스트 값만 허용되기 때문에
df.iloc[0,'칼럼명'] 과 같이 명칭을 입력하면 오류가 발생한다.
DataFrame loc[]
df.loc['로우명','칼럼명']과 같이 입력하여 사용할 수 있다.
여기서 index가 숫자형일 수도 있으니 무조건 문자열만 들어가는 게 아니라,
loc[1,'name']과 같이 입력하면 인덱스 값이 1인 행의 name 칼럼에 해당하는 데이터를 반환할 것이다.
loc[]에서도 슬라이싱이 가능하지만, 명칭은 숫자형이 아닐 수도 있기 때문에 종료값-1이 아니라 종료 값까지 포함된다는 점을 유의해야 한다! 특히 index가 정수형이면 loc[]를 이용할 때 조심해야 한다.
만약 loc[1:2,'name'] 을 입력하는 경우, 인덱스가 1과 2인 2개의 데이터를 반환하게 된다.
다시 한번 정리해보자.
- 명칭(label) 기반 인덱싱은 인덱스명이나 칼럼명으로 데이터에 접근하는 것=loc []
- 위치(position) 기반 인덱싱은 0부터 시작하는 행이나 열의 위치 좌표로 데이터에 접근하는 것=iloc[]
- ix[]는 둘 다 가능하지만 곧 사라질 예정이므로 최대한 사용을 피할 것.
- 명칭 기반 인덱싱에서 슬라이싱을 할 때는 시작점:종료점을 입력할 때 종료점까지 포함한다.
불린 인덱싱
드디어 가장 많이 사용하게 되는 불린 인덱싱 방식으로 넘어왔다.
원하는 값만을 필터링해서 가져올 수 있는 불린 인덱싱은 iloc[]를 제외한 [], ix[], loc[] 모두 지원된다.
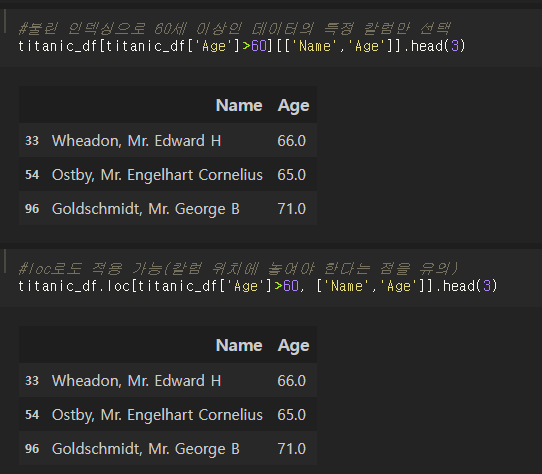
타이타닉 데이터에서 나이가 60세 이상인 데이터만 찾아보자.

조건을 만족하는 데이터의 특정 칼럼들만 선택할 수도 있다.
[]방식과 loc[] 방식 둘 다 이용할 수 있는데, 칼럼을 선택할 때 각각의 방식에 따른 위치와 괄호 사용에 주의하자.
복합 조건을 설정하거나 개별로 조건을 변수에 할당한 다음 합칠 수도 있다.
and 조건은 &
or 조건은 | (shift를 누른 채 백스페이스 아래에 있는 기호를 입력하여 선택 가능)
Not 조건은 ~
와 같은 연산자를 이용해주어야 한다.
두 가지 방법을 이용해서
나이가 60세 이상이고, 선실 등급이 1등급이고, 성별이 여성인 승객을 선택해보았다.

이렇게 특정 행 혹은 특정 열을 선택할 수 있는 방법에 대해서 알아보았다.
이번 내용의 원활한 이해를 위해 이전 포스팅 링크를 첨부해둔다 :)
판다스 기본 개념 정리하기
2022.08.07 - [Data Science] - [Pandas] 판다스 데이터프레임 기초 with 캐글 타이타닉 파일
2022.08.15 - [Data Science] - [Pandas] 넘파이 리스트 딕셔너리 판다스 변환
2022.08.15 - [Data Science] - [Pandas] Column 열 생성 및 삭제
2022.08.16 - [Data Science] - [Pandas] 판다스 인덱스 초기화 재정렬
넘파이 (numpy) 기초에 대한 공부가 필요하다면 아래 링크들을 참고 부탁드린다.
차근차근 넘파이 개념 정리하기
2022.08.02 - [Data Science] - [Numpy] 넘파이 설치+차원 확인+데이터 타입 확인 및 변경
2022.08.02 - [Data Science] - [Numpy] 넘파이 배열 생성 arange range 차이+파이썬 빈 배열 만들기
2022.08.03 - [Data Science] - [Numpy] 넘파이 reshape 차원 추가 축소 변경하기
2022.08.04 - [Data Science] - [Numpy] 넘파이 인덱싱 슬라이싱 팬시인덱싱 등으로 인덱스 반환하기 +찾기
2022.08.05 - [Data Science] - [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리
'Data Science' 카테고리의 다른 글
| [Pandas] 판다스 결측치 제거 대체 fillna(0) 간단히 응용하기 (0) | 2022.08.17 |
|---|---|
| [Pandas] 판다스 정렬 sort_values groupby (0) | 2022.08.17 |
| [Pandas] 판다스 인덱스 초기화 재정렬 (0) | 2022.08.16 |
| [Pandas] Column 열 생성 및 삭제 (0) | 2022.08.15 |
| [Pandas] 넘파이 리스트 딕셔너리 판다스 변환 (0) | 2022.08.15 |




댓글