
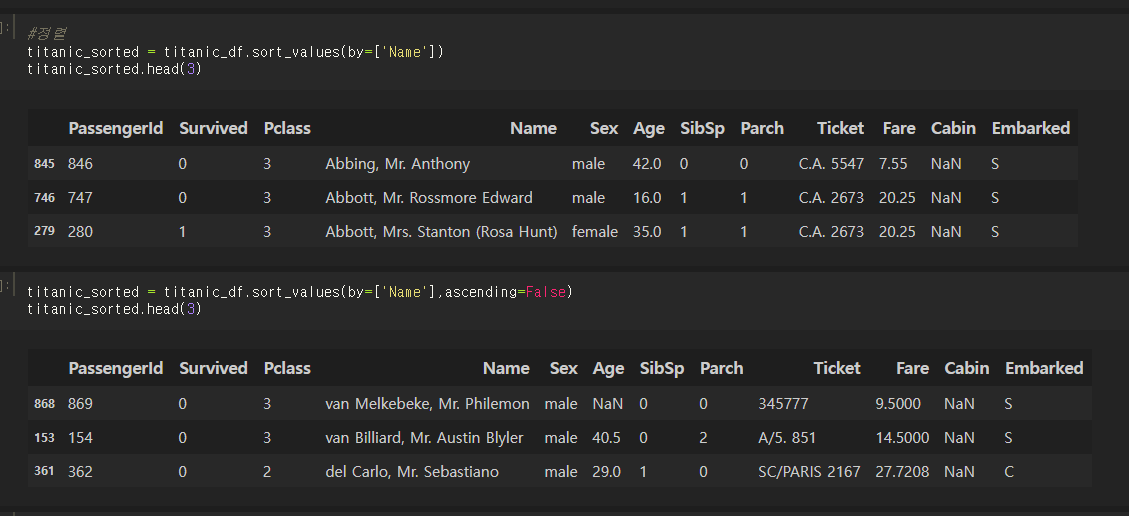
판다스 정렬 sort_values
데이터프레임과 시리즈 정렬 모두 sort_values()를 이용하면 된다.
sort_values는 RDBMS SQL의 order by와 매우 유사한 기능으로,
by=['칼럼명'] 으로 특정 칼럼 기준 정렬을 수행할 수 있고
ascending=True로 오름차순, False로 내림차순 정렬이 가능하다.(기본은 True 즉 오름차순)
inplace=True 로 데이터프레임의 정렬 결과를 그대로 적용할 수도 있다.(기본은 False)
판다스 Aggregation
SQL의 aggregation 함수와 비슷하게 min, max, sum, count와 같은 기초 통계량을 계산할 수 있지만,
판다스 Aggregation은 데이터프레임에서 바로 호출해서 칼럼들 전체에 적용할 수 있다.
예를 들어 df.count()를 적용해서 모든 칼럼의 결과를 반환할 수도 있고,
df[['Age','Fare']].mean() 과 같이 원하는 특정 칼럼만 선택해서 값을 확인할 수도 있다.
값을 계산할 때는 데이터 타입에 따라서 의미 있는 결과값을 도출할 수 있도록 유의하자.


판다스 groupby()
SQL의 groupby와 비슷하지만, 데이터프레임에서는 by='칼럼명'을 입력하면 대상 칼럼을 기준으로 그룹이 형성된다.
데이터프레임에 groupby()를 호출 시, DataFrameGroupBy라는 데이터프레임 객체가 반환된다.
보통은 groupby로 반환된 결과에 aggregation 함수를 적용한 결과를 바로 얻는다.
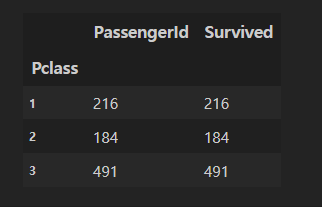
Pclass로 그룹화한 데이터들을 각 그룹별로 몇 개씩 있는지 count()를 이용해서 확인해보았다.

Select count(PassengerId), count(Survived) from titanic_table group by Pclass
SQL에서 위와 같이 해야 한다면,
데이터프레임에서는 아래와 같은 식으로 수행할 수 있다.
df_new = df.groupby('Pclass')[['PassengerId','Survived']].count()
만약 aggregation 함수를 여러개를 사용하고 싶다면, agg()내에 인자로 입력해야 한다.
SQL에서 Select max(Age), min(Age) from table1 groupby Pclass로 구현되었다면
df.groupby('Pclass')['Age'].agg([max,min]) 으로 구현할 수 있다.
agg()내에 딕셔너리 형태로 aggregation이 적용될 칼럼을 아래와 같이 각각 지정해줄 수도 있다.
agg_format={'Age' : 'max', 'SibSp' : 'sum', 'Fare' : 'mean'}
df.groupby('Pclass').agg(agg_format)
판다스 기본 개념 정리하기
2022.08.07 - [Data Science] - [Pandas] 판다스 데이터프레임 기초 with 캐글 타이타닉 파일
2022.08.15 - [Data Science] - [Pandas] 넘파이 리스트 딕셔너리 판다스 변환
2022.08.15 - [Data Science] - [Pandas] Column 열 생성 및 삭제
2022.08.16 - [Data Science] - [Pandas] 판다스 인덱스 초기화 재정렬
2022.08.16 - [Data Science] - [Pandas] 판다스 loc iloc 원하는 행 열만 선택하기 with 위치 기반, 명칭 기반 인덱싱의 이해
넘파이 (numpy) 기초에 대한 공부가 필요하다면 아래 링크들을 참고 부탁드린다.
차근차근 넘파이 개념 정리하기
2022.08.02 - [Data Science] - [Numpy] 넘파이 설치+차원 확인+데이터 타입 확인 및 변경
2022.08.02 - [Data Science] - [Numpy] 넘파이 배열 생성 arange range 차이+파이썬 빈 배열 만들기
2022.08.03 - [Data Science] - [Numpy] 넘파이 reshape 차원 추가 축소 변경하기
2022.08.04 - [Data Science] - [Numpy] 넘파이 인덱싱 슬라이싱 팬시인덱싱 등으로 인덱스 반환하기 +찾기
2022.08.05 - [Data Science] - [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리
'Data Science' 카테고리의 다른 글
| [Git] 초보가 자주 쓰는 필수 Git 명령어 모음 정리 (0) | 2022.09.11 |
|---|---|
| [Pandas] 판다스 결측치 제거 대체 fillna(0) 간단히 응용하기 (0) | 2022.08.17 |
| [Pandas] 판다스 loc iloc 원하는 행 열만 선택하기 with 위치 기반, 명칭 기반 인덱싱의 이해 (0) | 2022.08.16 |
| [Pandas] 판다스 인덱스 초기화 재정렬 (0) | 2022.08.16 |
| [Pandas] Column 열 생성 및 삭제 (0) | 2022.08.15 |




댓글