
우선 교차검증(Cross Validation)이란, 데이터 세트를 여러 개로 분리해서 다양하게 학습과 평가를 수행하는 것이다.
앞의 포스팅에서 설명했듯이 평가데이터를 생성하지 않고 100% 학습데이터를 만들었을 경우, 다른 새로운 데이터가 들어오면 제대로 적용하지 못하는 과적합(Overfitting) 문제가 발생하게 될 수 밖에 없다.
보통 8:2, 7:3과 같이 학습데이터와 평가데이터를 분리하는데, 이 방법도 과적합으로 인한 예측 저하가 생길 가능성이 있다. 이러한 문제를 해결하기 위해서 사용하게 된 것이 교차검증이다. 실제 어떤 새로운 데이터가 들어오더라도 잘 예측하는 것이 좋은 모델일텐데, 데이터를 마구 섞고 여러 번 학습과 평가를 거치면서 모델 최적화를 수행한다면 분명 더 좋은 모델을 생성하게 될 것이다.
K-Fold(케이폴드) 교차 검증
여기서 K는 나뉘어진 데이터 세트의 개수를 의미하며, K번만큼 학습과 검증, 평가를 반복적으로 수행한다.
만약 K=10이라면 내가 가진 데이터셋이 10등분이 될 것이다.
이렇게 나뉜 데이터셋을 1번, 2번,...10번으로 이름붙인다고 가정해보자.
첫 번째에는 1번~9번으로 학습, 10번으로 평가.
두 번째 반복 때는 1번~8번+10번으로 학습, 9번으로 평가.
....마지막으로는 2번~10번으로 학습, 1번으로 평가.
파이썬에서는 사이킷런 KFold, StartifiedKFold 클래스를 이용해서 K 폴드 교차 검증을 할 수 있다.
StartifiedKFold는 다음 포스팅에서 함께 설명 예정이다!
KFold(n_splits=10)과 같이 객체를 생성해준 다음,
kfold.split(features)로 데이터셋을 10개로 분리해준 다음 교차검증 수행 시마다 학습과 검증을 반복한다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# from sklearn.model_selection import train_test_split #이것 대신 KFold 데려오기
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
data = iris.data
target = iris.target
DTC = DecisionTreeClassifier(random_state=929)
kfold = KFold(n_splits=10)
cv_accuracy = []
print('iris dataset size : ',data.shape[0])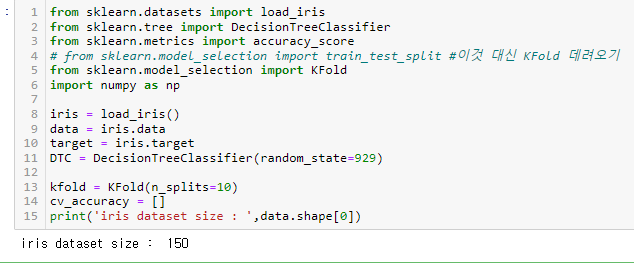
150개의 데이터가 있으므로, 데이터셋을 10개로 분리하면 각각 15개씩 10등분된다.
이제 10개의 폴드 셋을 생성하도록 KFold.split을 이용해 교차검증 수행 시마다 학습, 검증을 반복해서 정확도를 측정하고, split이 실제로 어떤 값을 반환하는 것인지 검증 데이터셋의 인덱스도 함께 확인해보자.
i=0
#KFold.split() 호출하면 폴드별 학습용, 검증용 테스트의 row index를 array로 반환함.
for train_index, test_index in kfold.split(data):
#kold.split으로 반환된 인덱스 이용해서 학습용 검증용 테스트 데이터 추출
X_train, X_test = data[train_index],data[test_index]
y_train, y_test = target[train_index],target[test_index]
#학습과 예측
DTC.fit(X_train, y_train)
y_pred = DTC.predict(X_test)
i+=1
#반복시마다 정확도 측정
accuracy = np.round(accuracy_score(y_test,y_pred),4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print(f'{i}번째 교차 검증 정확도 : {accuracy},train data size : {train_size},test data size : {test_size}')
print(f'{i}번째 검증 세트 인덱스:{test_index}')
cv_accuracy.append(accuracy)
#개별 정확도를 합해서 평균 정확도 계산
print('10평균 검증 정확도는 ', round(np.mean(cv_accuracy),4))
나누어진 데이터셋의 인덱스가 차례대로 돌아가면서 검증 세트가 되었다는 사실과 함께,
평균 검증 정확도가 약 94.67%가 도출되었음을 확인할 수 있다.
사이킷런 차근차근 공부하기
2022.09.30 - [Data Science] - [ScikitLearn] 사이킷런 분류 iris 품종 예측
2022.09.30 - [Data Science] - [ScikitLearn] 머신러닝 필수, scikitlearn 설치 및 사이킷런 버전 확인
함께 공부하면 좋은 판다스, 넘파이
2022.08.17 - [Data Science] - [Pandas] 판다스 결측치 제거 대체 fillna(0) 간단히 응용하기
2022.08.05 - [Data Science] - [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리
'Data Science' 카테고리의 다른 글
| [네이버 DataScience 스터디 8기] 부스트코스 강의 듣는 법 (0) | 2022.10.26 |
|---|---|
| [리드부스터 선정 후기] 네이버 Data Science 부스트코스 코칭스터디 8기 (0) | 2022.10.22 |
| [ScikitLearn] 사이킷런 분류 iris 품종 예측 (0) | 2022.09.30 |
| [ScikitLearn] 머신러닝 필수, scikitlearn 설치 및 사이킷런 버전 확인 (0) | 2022.09.30 |
| apply(lambda if) 함수 데이터프레임 Pandas if else 사용법 (0) | 2022.09.29 |




댓글