
sklearn.datasets를 이용하면 사이킷런에서 제공하는 데이터 세트를 생성할 수 있다.
특히 iris, 붗꽃 데이터셋은 load_iris로 생성할 수 있다.
오늘은 이 데이터를 이용해서
sklearn.model_selection으로 학습/검증/예측 데이터로의 데이터 분리 및 평가,
그리고 DecisionTreeClassifier, 의사결정나무로 학습과 예측을 수행해보고자 한다.
특히 최적의 학습과 머신러닝 알고리즘 성능 튜닝을 위해 직접 입력하는 파라미터를 하이퍼 파라미터라고 한다.
sklearn.tree에서는 트리 기반 ML 알고리즘을 구현한 클래스의 모임을 확인할 수 있다는 점만 확인하고 넘어가자.
먼저 필요한 라이브러리와 모듈을 import하고, 붓꽃 데이터셋을 가져와보자.
꽃받침 길이(Sepal length), 너비(Sepal sidth), 꽃잎 길이(Petal length), 너비(Petal width)라는 4가지 피처(feature)로 어떤 붓꽃 품종인지를 예측하는 모델을 생성할 수 있다.
import sklearn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
iris = load_iris()
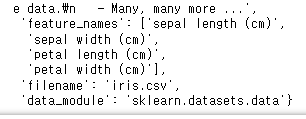
iris데이터 자체를 보면, nparray 형태로 들어있는 'data'와,
품종을 나타내는 레이블은 'target'으로 0,1,2 세 가지 값으로 되어 있고,
'target_names'가 'target' 0에 setosa, 1에 versicolor, 2에 virginica로 매칭 되어 있다.
또한 데이터셋에 대한 설명(DESCR)과 함께 'feature_names'에 위에서 말했던 feature이 들어있으며,
filename은 iris.csv, data_module은 sklearn.datasets.data로 어떤 모듈에 들어있었는지도 볼 수 있다.
*대부분 data는 데이터셋, target은 분류할 결과(레이블)의 값으로 넘파이 배열(ndarray) 타입,
target_names는 분류할 결과(레이블)의 이름, feature_names는 피처의 이름으로 ndarray나 list 타입이다.
이 항목들을 키값(key)이라고 하는데 load_iris.keys()를 이용해서 딕셔너리 형태로 가져올 수 있다.


데이터프레임에 피처 이름에 따라 데이터를 담아주고, 어떤 값으로 분류할지를 결정하기 위해 target_label 값도 넣어줬다.
iris_data = iris.data
iris_target = iris.target
df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
df['target_label']=iris.target
df.head()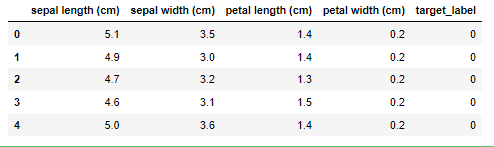
train_test_split()
만약 내가 가진 데이터를 100% 활용해서 학습을 시킨다면, 다른 새로운 데이터셋에 적용을 할 수 없는 과적합(overfitting) 문제가 발생할 수밖에 없다. 그래서 테스트할 데이터로 약 20~40% 정도를 남겨두고, 나머지 데이터로 학습을 시키는 과정이 필수적이다.
train_test_split()을 이용해 모델을 학습시킬 학습 데이터와,
얼마나 잘 모델이 생성되었는지 평가하기 위한 테스트 데이터를
test_size 파라미터 입력 값의 비율을 설정해서 분리해줄 수 있다.
만약 test_size = 0.3을 입력한다면 70%의 데이터로 학습을 하고, 30% 데이터로 해당 모델을 평가하게 될 것이다.
#train_test_split()
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target,
test_size=0.2, random_state=11)iris_data(X)를 iris_target(y)로 분류하기 위해서는 파라미터를 이렇게 차례대로 설정해줘야 한다.
1. iris_data : 피처 데이터셋(X). X_train과 X_test로 나뉘었다.
2. iris_target : 레이블 데이터셋(결론적으로 무엇으로 분류하고 싶은지, 여기서는 꽃의 품종)(y). y_train과 y_test로 나뉘었다.
3. test_size : 테스트 데이터셋의 비율 설정
4. random_state : 호출할 때마다 같은 학습/테스트용 데이터 세트를 생성하기 위해 주어지는 난수발생 값. 원래는 train_test_split()을 호출하면 데이터가 무작위로 분리되는데, 이렇게 되면 매번 다르게 데이터가 분리되므로 이번에는 동일하게 분리해주기 위해 설정했다. 숫자 자체는 어떤 값이든 상관없다.
#DecisionTreeClassifier
#여기서도 random_state=11은 동일한 학습/예측 결과를 출력하기 위한 것 뿐, 의미 없음.
#fit()에 학습용 피처 데이터 속성과 결정값 데이터셋을 입력하면 학습 시작.
DTC = DecisionTreeClassifier(random_state=11)
DTC.fit(X_train, y_train)의사결정나무 기반으로 학습 데이터를 이용해 fit만으로 간단히 학습이 완료됐다.
이제 예측을 수행할 수 있는데, 당연히 학습 데이터가 아니라 남겨놓은 테스트 데이터셋을 이용한다.
한 줄의 코드로 간단하게 수행하고 y_pred에 예측한 결과를 저장해보자.
y_pred = DTC.predict(X_test)위의 과정에서 느낄 수 있듯이, 분류와 회귀 알고리즘은 모두 fit()으로 머신러닝 모델 학습, predict()로 예측을 수행한 결과를 아주 간단히 반환할 수 있다.
* 사이킷런에서는 Classifier(분류 알고리즘을 구현한 클래스), Regressor(회귀 알고리즘을 구현한 클래스)를 합쳐서 Estimator 클래스라고 부르기 때문에, Estimator 클래스가 나오더라도 당황하지 않고 fit()과 predict()를 사용하면 된다. (cross_val_score, GridSearchCV 등)
비지도 학습(차원 축소, 클러스터링)과 피처 추출 시에는 fit()을 학습이 아니라 데이터 변환을 위해서 사전 구조를 맞추는 데 사용하고, 이후 transform()으로 실제 작업을 수행하게 된다.
마지막으로 우리가 예측한 y_pred와, 테스트를 위해 남겨놓은 y_test가 얼마나 일치하는지를 확인하기 위해
accuracy_score() 함수를 이용해서 결과를 확인해보니 0.9333, 즉 93.33%의 정확도를 가지는 의사결정트리 알고리즘이 만들어졌음을 알 수 있었다.
from sklearn.metrics import accuracy_score
print(round(accuracy_score(y_test, y_pred),4))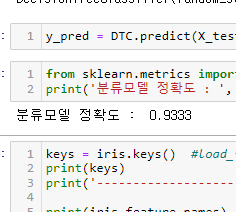
정리
정리하자면, 분류 예측 프로세스는 아래와 같이 진행된다.
학습 데이터셋/평가 데이터셋으로 분리
->모델 학습
->모델을 이용해 분류 예측
->모델 성능 평가
사이킷런 차근차근 공부하기
2022.09.30 - [Data Science] - [ScikitLearn] 머신러닝 필수, scikitlearn 설치 및 사이킷런 버전 확인
함께 공부하면 좋은 판다스, 넘파이
2022.08.17 - [Data Science] - [Pandas] 판다스 결측치 제거 대체 fillna(0) 간단히 응용하기
2022.08.05 - [Data Science] - [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리
'Data Science' 카테고리의 다른 글
| [리드부스터 선정 후기] 네이버 Data Science 부스트코스 코칭스터디 8기 (0) | 2022.10.22 |
|---|---|
| [ScikitLearn] 사이킷런 교차검증 파이썬 뜻과 이유 K-Fold (0) | 2022.10.12 |
| [ScikitLearn] 머신러닝 필수, scikitlearn 설치 및 사이킷런 버전 확인 (0) | 2022.09.30 |
| apply(lambda if) 함수 데이터프레임 Pandas if else 사용법 (0) | 2022.09.29 |
| 비전공자 데이터분석 가능할까? 데이터시각화부터 시작하기 (0) | 2022.09.17 |




댓글