
넘파이 인덱싱은 ndarray의 특정 데이터를 골라서 반환하도록 만드는 것이다.
만약 한 개의 데이터 값을 선택하려면 ndarray 안에서 찾고자 하는 값의 인덱스를 [] 안에 입력하면 된다.
인덱스는 0부터 시작하므로,
array라는 1차원 배열의 1번째 값을 선택하고자 한다면 array[0]
array라는 1차원 배열의 3번째 값을 선택하고자 한다면 array[2] 와 같이 입력하면 된다.
마이너스 기호를 이용해 array[-1]과 같이 맨 뒤의 데이터를 찾을 수 있다.
맨 앞 데이터 인덱스는 0이고, 맨 뒤 데이터 인덱스는 -1이다.
이런 방식으로 특정 인덱스 값 변경도 가능하지만, ndarray에서는 원본 값이 바로 수정되어버리기 때문에 리스트로 변환하여 작업하는 경우가 흔하다.(리스트는 값을 바꾸어도 원본이 수정되지는 않기 때문이다)
2차원 넘파이 인덱싱
1차원에서는 이렇게 간단하게 작업을 할 수 있지만, 2차원에서는 행과 열에 익숙해져야 한다.
행 인덱스 시작도 0부터, 열 인덱스 시작도 0부터임을 잘 기억하자.
좀 더 익숙해지기 위해서
1) 9개의 데이터가 있는 리스트 생성
2) 리스트를 배열로 변경
3) 생성된 배열 차원 변경(3x3 2차원으로)
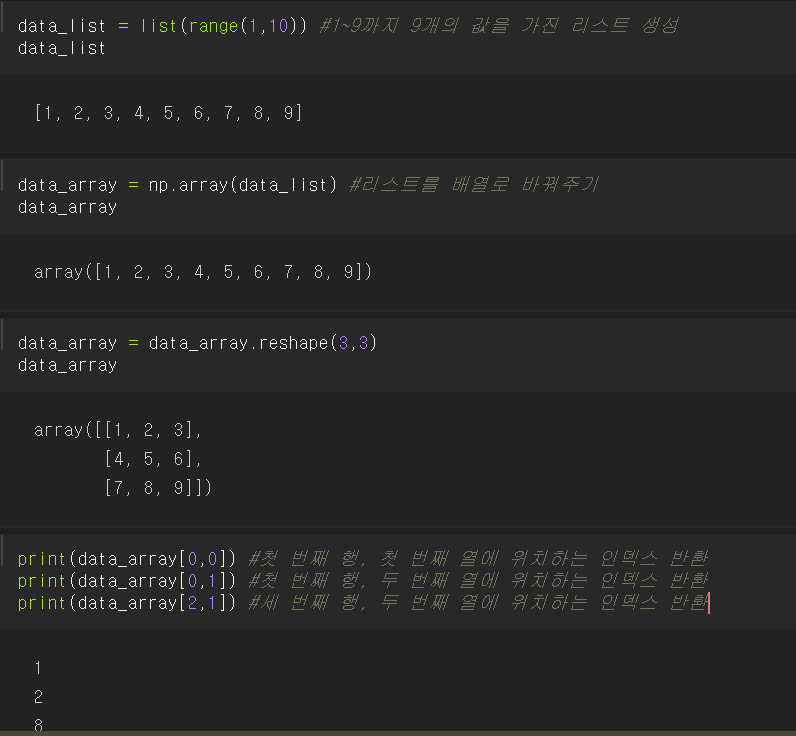
배열이름[행,열] 로 인덱스 반환이 완료되었다.
data_array 를 보면서 각각 어떤 인덱스를 추출한 것인지 파악해보면 공부에 많은 도움이 된다!
그런데 배열에 익숙해지려면 행과 열이 아니라 또 다른 이름에 익숙해지는 게 좋다.
행, 즉 ROW 방향의 축은 axis 0
열, COLUMN 방향의 축은 axis 1이라고 부른다.
3차원 배열이라면 axis 0, axis 1, axis 2라는 3개의 축을 가지게 될 것이다.
넘파이 슬라이싱 1차원
넘파이 슬라이싱 또한 인덱싱의 한 종류로, 미끄러지듯이 특정 구간의 데이터를 반환할 수 있다.
배열이름[시작인덱스:종료인덱스] 로 입력하면 시작 인덱스에서 종료 인덱스의 직전 값까지 반환한다. 즉, 종료 인덱스는 포함하지 않는다.
위에서 사용했던 data_array를 다시 data_array1이라는 1차원 배열로 바꾸어서 슬라이싱 해보자.
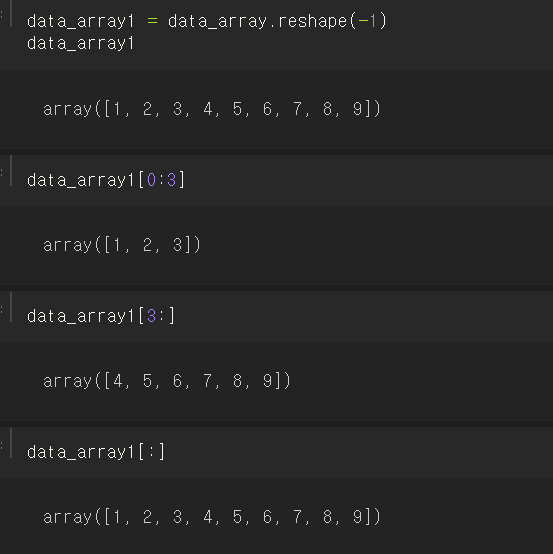
data_array1[0:3] 은 인덱스 0부터 3 직전까지 즉 0,1,2라는 인덱스를 뽑아낸다. 다시 말해 첫 번째, 두 번째, 세 번째 값을 반환한다.
data_array1[3:]은 인덱스 3부터 끝까지 반환하라는 뜻이며,
data_array1[:]은 처음부터 끝까지 모든 인덱스를 달라는 뜻이다.
넘파이 슬라이싱 2차원
2차원에서는 특정 블록을 선택한다고 생각하면 편할 것 같다. 예시를 통해 확인해보자.

1부터 9까지 9개의 데이터를 가지는 3x3 2차원 배열인 data_array가 있다.
여기서 data_array[0:2,0:2]는
axis 0 (ROW개념)의 인덱스 [0], [1]
axis 1 (COLUMN 개념)의 인덱스 [0], [1]을 반환할 것이다.
그리고 data_array[1:3,:]은
axis 0의 인덱스 [1], [2] 그리고 axis 1의 전체 데이터를 반환하게 된다.
넘파이 팬시 인덱싱
특정 구간의 범위를 선택하는 게 아니라, axis 0에서 3번째, 1번째만 선택하고 싶을 때 사용하는 게 팬시 인덱싱이다.
콕 집어낼 수 있다는 점에서 fancy라는 단어가 잘 어울리지 않나 싶다.
유의할 점은 슬라이싱과는 다르게 괄호[]가 추가되어야 한다.
동일하게 data_array를 이용해 살펴보자.

data_array[[0,2],0:2] 는 다음을 의미한다.
axis 0의 인덱스 0, 인덱스 2를 선택하고 : (1, 2, 3) 그리고 (7,8,9)
axis 1의 인덱스 0~인덱스 1을 선택해라 : (1,2) 그리고 (7,8)
넘파이 불린 인덱싱 (불리언)
불리언 인덱싱이라고도 하는 불린 인덱싱은, 조건을 주고 검색을 할 수 있어서 가장 유용하다.
특정 조건을 만족하면 True, 만족하지 않으면 False를 반환하게 되며 이를 이용해서 원하는 데이터만 뽑아낼 수 있다.
1. 배열에 조건식을 할당하면 True와 False로 이뤄진 ndarray 객체를 반환한다.
2. 이 ndarray를 인덱싱을 지정하는 [] 안에 넣어주면 True인 인덱스 위치의 데이터만 반환하게 된다.
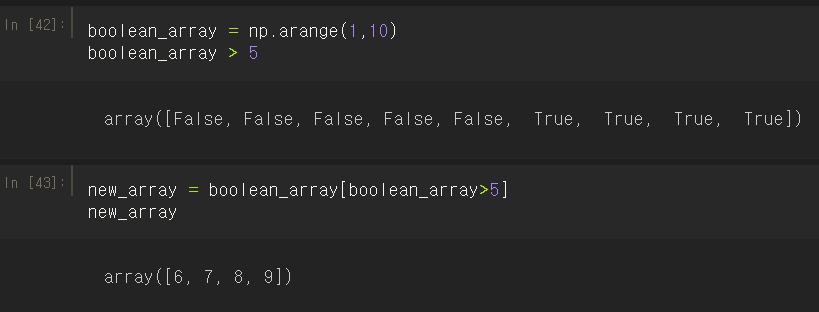
1부터 9까지의 1차원 배열을 만든 다음 불린 인덱싱을 이용해 원하는 조건(5 이상)에 맞는 데이터만으로 배열을 다시 만들었다.
꼭 기억해야 하는 점은 42번 셀의 결과에 []가 있는 것에서 볼 수 있듯이, True 값 자체인 1을 저장하는 게 아니라 "True값을 가진 인덱스"를 저장한다는 점이다.
*만약 특정 조건을 만족하는 인덱스를 찾고 싶다면 불린 인덱싱과 같이 배열에 대한 조건을
np.where(조건) 과 같이 입력해서 찾을 수 있다.
차근차근 넘파이 개념 정리하기
2022.08.02 - [Data Science] - [Numpy] 넘파이 설치+차원 확인+데이터 타입 확인 및 변경
2022.08.02 - [Data Science] - [Numpy] 넘파이 배열 생성 arange range 차이+파이썬 빈 배열 만들기
2022.08.03 - [Data Science] - [Numpy] 넘파이 reshape 차원 추가 축소 변경하기
'Data Science' 카테고리의 다른 글
| [Pandas] 판다스 데이터프레임 기초 with 캐글 타이타닉 파일 (0) | 2022.08.07 |
|---|---|
| [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리 (0) | 2022.08.05 |
| [Numpy] 넘파이 reshape 차원 추가 축소 변경하기 (0) | 2022.08.03 |
| [Numpy] 넘파이 배열 생성 arange range 차이+파이썬 빈 배열 만들기 (0) | 2022.08.02 |
| [Numpy] 넘파이 설치+차원 확인+데이터 타입 확인 및 변경 (0) | 2022.08.02 |




댓글