
판다스란
대부분 우리가 다루는 데이터는 행(Row)과 열(Column)으로 구성돼 있는 2차원 데이터다. 가장 효과적인 데이터 구조이면서 이해하기도 쉽기 때문인데, 판다스 라이브러리는 이런 2차원 데이터 핸들링을 효율적이고 편하게 만들어준다.
csv나 txt, 등 다양한 유형의 "구분 기호로 칼럼이 분리된 파일"을 쉽게 데이터프레임으로 불러와서 작업할 수 있다.
판다스 데이터프레임 시리즈 차이
그럼 판다스 데이터프레임, pandas dataframe이란 무엇일까?
먼저 데이터프레임(Dataframe)은 위에서 말한 행과 열로 만들어진 2차원 데이터로, 여러 개의 칼럼을 가지는 데이터 구조체다.
만일 칼럼이 하나뿐이라면 이를 시리즈(Series)라고 부른다.
즉 DataFrame은 여러 개의 Series로 이뤄졌다고 할 수 있겠다.
* Index는 개별 데이터를 고유하게 식별하는 키값이라는 점을 참고로 짚고 넘어가자.
캐글 데이터 다운로드
캐글의 시작이라고 할 수 있는 타이타닉 데이터를 다운로드하여보자. kaggle 사이트에 접속해서 회원가입을 해야 데이터셋을 다운로드할 수 있다. 대부분 경연의 예제라서 참가 규정과 관련하여 I understand and accept 버튼을 클릭해야 받을 수 있다.

데이터 탭을 클릭해서 아래로 내려보면 train.csv 데이터셋이 있다. 이 파일을 원하는 경로에 옮겨 저장해 주자.
csv 파일이기 때문에 '쉼표로 구분'되어 있다.

판다스 csv 불러오기 API는 read_csv()로, 쉼표로 구분된 파일을 불러와서 데이터프레임으로 변환한다.
만일 쉼표가 아닌 특정 구분 문자(: 등)로 분리가 되어 있다면 sep=':'와 같이 sep 인자에 해당 구분 문자를 입력하면 된다.
탭('\t)으로 분리된 파일 불러오기는 read_table()로도 가능하지만, read_csv()로도 가능하다.
read_fwf()도 있는데, 고정된 길이의 칼럼(Fixed Width)을 데이터프레임으로 불러오는 것이며 그렇게 자주 사용하지는 않는듯하다.
read_csv(파일 경로, sep='구분 문자')와 같은 형식으로 불러오면 된다.
파일을 저장한 경로에 주피터 노트북 파일을 하나 생성해서 데이터를 확인해보았다.
만일 pandas read csv header를 없애거나 지정하고 싶다면 불러올 때 header=None이나 특정 행을 지정해줄 수도 있다.

보통 pd로 import를 많이 하고, 데이터프레임명은 줄여서 df라고 사용하는 경우가 많다.
(하지만 이는 연습할 때고, 실무에서는 뭐니 뭐니 해도 이해가 쉽고 알아보기 쉬운 이름이 최고다.)
나는 같은 경로에 저장해주었으므로 상대 경로를 지정해주었는데, C:\Users\~~처럼 절대 경로로 지정해줘도 된다!
데이터프레임명.head(숫자) 와 같이 처음 몇 행만을 불러와서 확인해볼 수 있다. Default는 5개.
판다스 데이터 타입 확인
pandas data type은 type(데이터프레임명)으로 할 수 있다.
맨 왼쪽 부분이 바로 인덱스! (PassengerId처럼 만일 파일 내에 따로 다른 인덱스가 있다면 csv 내보내기를 할 때 없앨 수도 있는데, 데이터베이스 관점으로 볼 때 꼭! 각 데이터의 고유한 값을 Key로 사용해주어야 한다.)

단순히 df1으로 데이터 전체를 확인해볼 수도 있다. 가장 하단에서 데이터프레임 크기 확인이 가능하다.
891 rows와 12 colums로 구성되어 있는데, 데이터프레임명.shape() 변수를 써서 행, 열 튜플 형태로 반환도 가능하다.
pandas info describe


왼쪽이 pandas info이고 오른쪽이 pandas describe이다.
info() 메서드로는 총 데이터 건수, 칼럼 별 데이터 타입, Null 값이 있는지의 여부를 알 수 있다.
describe()는 칼럼별 기초 통계량들(사분위수, 최솟값, 최댓값, 평균, 표준편차)을 확인할 수 있다.
유의할 점은 info에서 확인했던 Name, Age와 같은 object 타입(문자열 타입)은 제외된다는 점, count는 Null값이 아닌 데이터의 건수를 나타낸다는 점이다.
describe 메서드에서 정보를 빠르게 확인할 수 있는데, Survived나 Pclass는 숫자형 카테고리 칼럼일 것으로 추정 가능하다.
Pclass 칼럼을 Series 형태로 반환한 다음, value_counts()로 유형과 건수를 확인할 수 있는데, value_counts()는 굉장히 많이 쓰이지만 시리즈 객체에서만 정의되어 있다는 점을 기억하자.
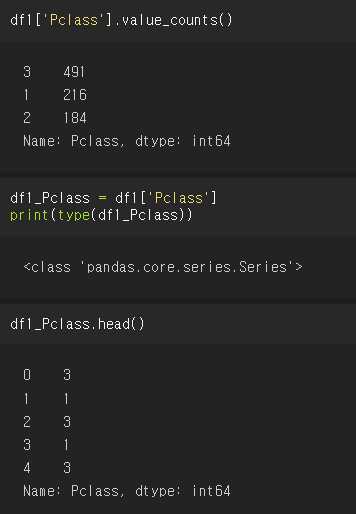
위에서 value_counts()로 확인한 데이터는 index가 3,1,2로 되어있는데, 고유성이 보장된다면 의미 있는 데이터 값의 할당도 가능하다는 것! 칼럼 값 별로 데이터 건수를 반환하니까 고유한 칼럼 값을 식별자로 사용할 수 있는 것이다.
정리하자면, 각각 아래와 같은 결과가 나온다는 것!
value_counts()로 뽑아냈을 때는 칼럼 값별로 데이터 건수를 반환하는 Series
단순히 데이터프레임명['칼럼명'] 으로 뽑아냈을 때는 값이 쭉 나열되는 Series
판다스 데이터프레임은 사실 너무 무궁무진해서 기본적인 기능들만 정리를 해두고, 프로젝트들을 직접 해보면서 조금씩 기능들을 추가로 알아가는 것이 좋다 :) 칼럼 생성, 필터링, 결손 데이터 처리, 데이터 삭제, 인덱싱과 Groupby 정도가 자주 쓰는 기능인 것 같은데 빠르게 정리하고 본격적인 머신러닝을 위한 사이킷런 실습으로 들어가고자 한다!
넘파이 (numpy) 기초에 대한 공부가 필요하다면 아래 링크들을 참고 부탁드린다.
차근차근 넘파이 개념 정리하기
2022.08.02 - [Data Science] - [Numpy] 넘파이 설치+차원 확인+데이터 타입 확인 및 변경
2022.08.02 - [Data Science] - [Numpy] 넘파이 배열 생성 arange range 차이+파이썬 빈 배열 만들기
2022.08.03 - [Data Science] - [Numpy] 넘파이 reshape 차원 추가 축소 변경하기
2022.08.04 - [Data Science] - [Numpy] 넘파이 인덱싱 슬라이싱 팬시인덱싱 등으로 인덱스 반환하기 +찾기
2022.08.05 - [Data Science] - [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리
'Data Science' 카테고리의 다른 글
| [Pandas] Column 열 생성 및 삭제 (0) | 2022.08.15 |
|---|---|
| [Pandas] 넘파이 리스트 딕셔너리 판다스 변환 (0) | 2022.08.15 |
| [Numpy] argsort 넘파이 정렬 내림차순까지 간단히 정리 (0) | 2022.08.05 |
| [Numpy] 넘파이 인덱싱 슬라이싱 팬시인덱싱 등으로 인덱스 반환하기 +찾기 (0) | 2022.08.04 |
| [Numpy] 넘파이 reshape 차원 추가 축소 변경하기 (0) | 2022.08.03 |




댓글